
The majority of today’s artificial neural network (ANN) architectures perform a constant amount of computation at inference time regardless of their inputs. This includes all recent GPT-style LLMs1 and other transformer-based architectures.
Whether you ask an LLM to complete the series “1, 2, 3, …”, or you ask it to solve a complicated logic riddle, the exact same amount of compute will be spent on predicting each token of its response.
Intuitively, it should be clear that this constraint means at least one of the following:
- LLMs waste a significant amount of computation on simple tasks
- or, LLMs are unable to solve complex tasks due to being limited in their compute per token.
In reality, a combination of both statements appears to be true depending on the prompt.
One approach to overcome the constant-computation limitation of LLMs is “chain of thought” prompting (Wei et al. 2022). By requesting that an LLM lays out each step along the way to an answer, the LLM no longer has to come up with its final answer in a single token inference pass. Rather, we allow it to spend compute proportional to the number of steps needed to solve a challenging question.
Other applications of ANNs are not as fortunate: A self-driving car will typically make control decisions at a fixed rate, and without the ability to “build up” more complex thoughts over time. No matter whether the current traffic situation is highly complex, or whether the car is simply following a lane on an empty highway.
Back in 2021, while in-between jobs, I set out to see if I could get an ANN to perform a variable amount of computation in order to solve arithmetic tasks of varying difficulty.2 In this post, I’ll explain the neural architecture that I came up with, and show some results on a toy problem.
Think as Long as Necessary, But as Short as Possible
In the following, I’ll describe a neural network architecture that, for lack of a less pretentious name, I’m going to refer to as ThoughtNet.
ThoughtNet operates on a fixed-length sequence of input tokens. Its principal architecture is as follows:
- Transform each input token into an internal state space (expansion).
- Repeatedly route each token’s internal state representation through a number of learned operators. One operator is selected for each token, and its result is integrated back into the token’s internal state to be used by subsequent iterations.
- Once the state has reached a fixed point, project the internal state space back into output tokens (reduction).
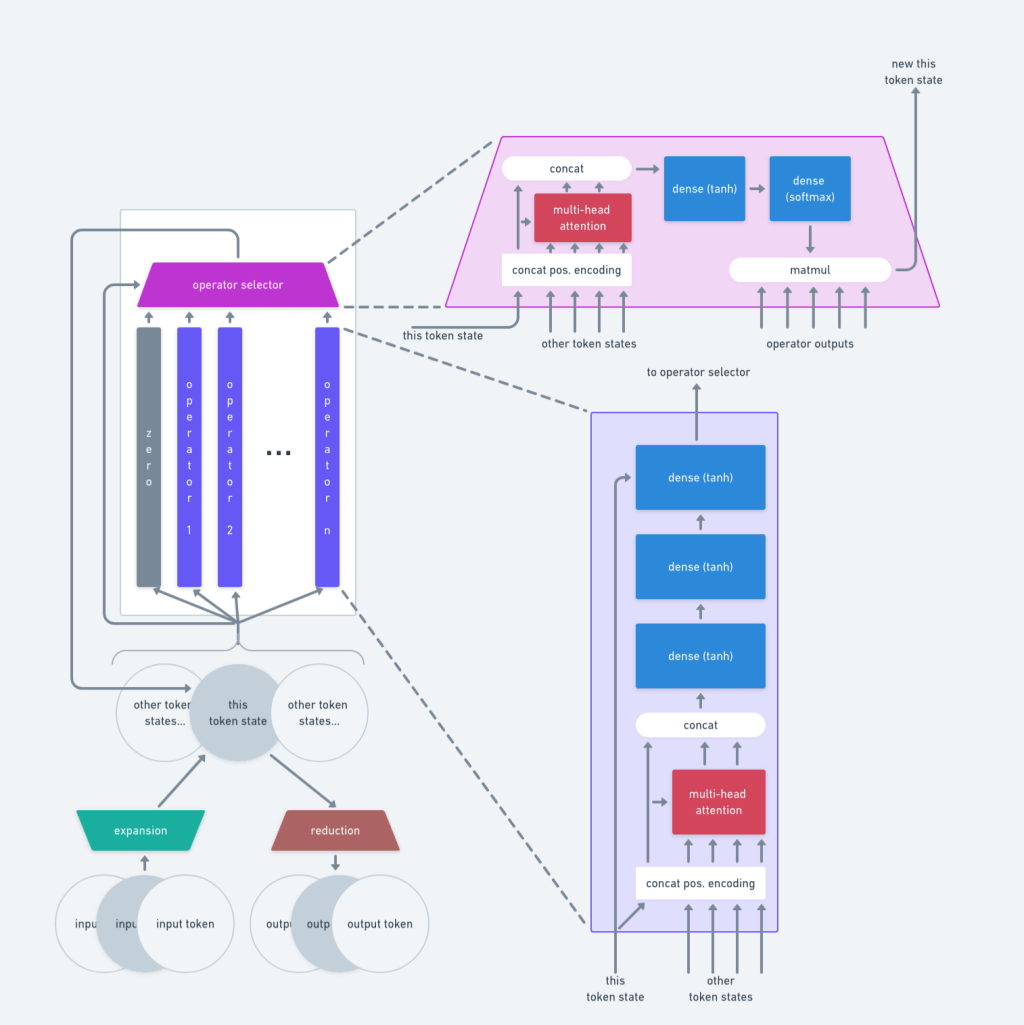
Learned Operators
Operators receive the token’s current internal state and produce a new representation that replaces the token’s state for the next iteration. Additionally, operators can access the state of other tokens through a self-attention mechanism. The self-attention mechanism used is similar to the one proposed in Attention Is All You Need (Vaswani et al. 2017), including the use of cosine/sine positional encodings. Though I decided to concatenate the positional encodings onto the state vectors rather than adding it over them.
As you can see from the network diagram above, I’m utilizing a residual link that feeds the current token’s state directly into the operator’s final layer. This makes it easy for an operator to carry over specific attributes from the previous state. The fully connected (dense) layers within the operators use tanh activation functions. Other activation functions can work as well, but it is beneficial to constrain the numerical range of activations as it makes our fixed-point criteria work better. I will discuss the reason for this shortly.
Operator Selection
Conceptually, the network chooses one operator for each token to apply in a given iteration. In practice, a softmax-weighted selection mechanism is used to make operator selection differentiable. See the “operator selector” component in the diagram above for its exact inner workings.
Reaching a Fixed Point
As mentioned above, ThoughtNet keeps applying operators to each token until a fixed point is reached. But how do we know when a fixed point has been reached?
The solution is to add a special “identity” or “zero” operator. The zero operator is hard-coded to output a token’s current state unchanged. The zero operator can be selected through the usual operator selection mechanism, just like any of the other learned operators.
For a given sequence of input tokens, we determine that a fixed point has been reached once the total weight assigned by the operator selector to operators other than the zero operator is below a stopping threshold (e.g. 0.2) across all tokens.
But aren’t there some problems with this approach?
- Why would the network reach a fixed point at all? Is there anything stopping it from oscillating between different, possibly even equivalent states, or just drifting indefinitely?
- What if the network learns its own version of an identity operator? While the token states might reach a fixed point, our criteria would fail to recognize this fact if the network decides to use this custom identity operator instead of the hard-coded zero operator.
- Since we’re not requiring the weight on non-zero operators to quite reach 0, but conclude that a fixed point has been reached below some threshold > 0, how do we know that the state values weren’t still going to change significantly in the current or a future iteration?
To answer question 3 first: Indeed, our fixed-point criteria is approximate and does not guarantee that future iterations won’t further change the token states. However, we can encourage a certain degree of “smoothness” over the operators to make the criteria “more correct”. We do so by a) using a weak L2 weight regularizer across all layers, thereby discouraging large derivatives in their activations, and b) using a tanh activation function to constrain the total magnitudes of state values across iterations.
The answer to questions 1 and 2 can be found in the following addition:
Encouraging Limited Computation
To encourage the network to think less, I impose a “thought cost” on each iteration. One iteration here refers to a single pass of the internal state through the various operators and the operator selector. The thought cost for a given iteration i (numbered 0, …, max_iteration) is computed as follows:
- Take the operator selection vector, i.e. the output of the softmax layer within the operator selector. Set the first component, which corresponds to the zero operator, to zero.
- Compute the L1 norm of this masked selection vector.
- Scale the cost linearly by the iteration number i. The first iteration is free, but utilizing non-zero operators in subsequent iterations becomes increasingly expensive.
The overall thought cost for a given input is the sum of the per-iteration costs. It is then scaled by an “urgency” constant (e.g. 0.0002 in my experiments) before being added to the training loss.
This thought cost regularizer pushes the network towards utilizing the zero operator as soon as possible. In particular, once applying another operator no longer improves the network’s output, the operator selector is incentivized to choose the zero operator exclusively. Furthermore, because utilizing non-zero operators becomes increasingly expensive in later iterations, we encourage ThoughtNet to spend all of its thinking “budget” early on, and then stick to the zero operator for all remaining iterations.
During training time, the number of iterations is fixed to some maximum (e.g. 10). But at inference time, we can now cut computation short by applying the fixed-point heuristic described above.
What’s the Urgency?
The urgency value does not need to be constant. You can imagine scenarios where urgency could be variable. For example, an artificial lifeform or autonomous vehicle might require a decision with high urgency when it’s sensing a dangerous situation or moving at high speeds, while it can expand more thought time when in a safe situation.
This can be modeled in ThoughtNet by providing the urgency factor on a per-data-point basis, and simultaneously making it available as an input to the operator selector network. By exposing ThoughtNet to training samples with different urgency values, the operator selector would learn how to compute the best approximate results in limited time when urgency is high, while expanding more (non-zero) iterations in order to get more accurate results when urgency is low. I did not have time during my experiments to implement variable urgency, so validating this idea is left for future work.
Does it Work?
I evaluated ThoughtNet on a simple toy problem: Addition and multiplication arithmetics on natural numbers. I selected this particular evaluation problem for two reasons:
- Addition and, even more so, multiplication require multiple steps to arrive at the final result. Addition requires a variable number of carries, and multiplication requires several additions. The number of steps required depends on the size and values of the input.
- By co-training on both addition and multiplication, I also hoped to exercise operator re-use. My hope was that multiplication could share common operators with addition to compose the more complex multiplication procedure.
Input Encoding
The input is a sequence of tokens, where each token represents either a single digit (0-9), or an operator character (* or +). All tokens are encoded as one-hot vectors. All numbers are padded to 4 digits. Each input consists of two numbers and a single operator in between them. For example “0023+0123”.
The desired output is the result of the calculation. For example “000000146”.
Loss Function and Metrics
I’m using categorical cross-entropy as the main training loss, complemented by the thought cost / urgency regularizer described above.
For evaluation purposes, I also calculate a simple sequence accuracy, which assigns a value of 1 whenever an input sample is converted to the exactly correct output sequence, and 0 otherwise. Sequence accuracy is not a good metric for training, since its derivative is 0 almost everywhere. However, it provides a more intuitive measure of the network’s performance on the arithmetics data set.
Data Set
The data set used for the below evaluation is composed of the following 15,000 training samples:
- 500 randomly sampled single-digit additions (1-digit + 1-digit)
- 2,000 randomly sampled 2-digit + 2-digit additions
- 5,000 randomly sampled 3-digit + 3-digit additions
- 500 randomly sampled single-digit multiplications
- 2,000 randomly sampled 1-digit * 2-digit and 2-digit * 1-digit multiplications
- 5,000 randomly sampled 2-digit * 2-digit multiplications
Due to this sampling distribution, all combinations of single-digit pairs are likely present multiple times in the training set, while inputs with a total of 4 or more input digits are only sparsely represented.
For the evaluation below, separate test sets were generated using an independent sampling of the desired operation and number of digits.
Optimization
I used backpropagation with the Adam optimizer to train the network for 1,000 epochs, using micro batches of size 250. The learning rate followed the following stepwise constant schedule:

Results: Accuracy
Convergence of ThoughtNet was relatively slow in my experiments, but eventually achieved 100% sequence accuracy on the training data after about 500 epochs. Faster training rates made convergence faster initially, but caused oscillating patterns to become more destructive.


For addition, test set performance was similarly good, with above 99% sequence accuracy on all tested input sizes, all the way up to 3-digit + 3-digit (total of 6 digit) inputs. This shows strong generalization capabilities on addition tasks, given that the majority of 3+3 digit inputs was not present in the training data.
For multiplication, test set performance was less stellar. For 1-digit * 2-digit and 2-digit * 1-digit inputs, sequence accuracy already shrunk to 88%. For 2-digit * 2-digit multiplication, accuracy was reduced further to 51%. 51% is approximately the rate that could be achieved by simple memorization of training samples. Therefore, my experiments did not illustrate good generalization beyond the training data on multiplication tasks. This is an area for further investigation.
PS: In this follow-up post, I investigate additional regularization that improves training convergence as well as test set performance.
Results: Thought Cost
What about the main premise of ThoughtNet, that the network could learn to expend less computation on simple inputs, and more on difficult ones?
The following graphs show the thought cost for inputs of different digits, once for addition and then for multiplication. Thought cost values are shown prior to multiplication with the urgency constant.

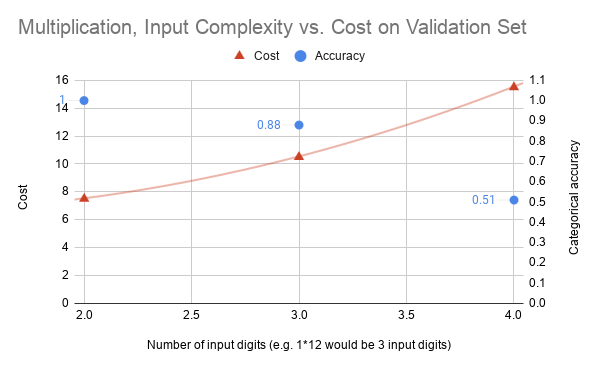
Indeed, thought cost for a given number of input digits is higher for multiplication than for addition, in line with the intuitive level of complexity for these two operations. Furthermore, within one operation, the thought cost utilized by the network scales nicely with the size of the input.
The introduction of a thought cost / urgency loss, in conjunction with the ThoughtNet model architecture, appear to elicit the desired result of enabling input-dependent, variable-time computation in an artificial neural network.
Example Runs
Below, you can see a visualization of the operator selection vectors (left column) and the state vectors (right column) across each iteration of the given inference. Each row corresponds to a different token.
Example 1: 29+66 -> 95

Non-zero operators were chosen for a subset of tokens in the first two iterations. In the third iteration, the operator selector selected the zero operator for all tokens, triggering the fixed-point criteria and early termination of the inference process.
Example 2: 29*66 -> 1914
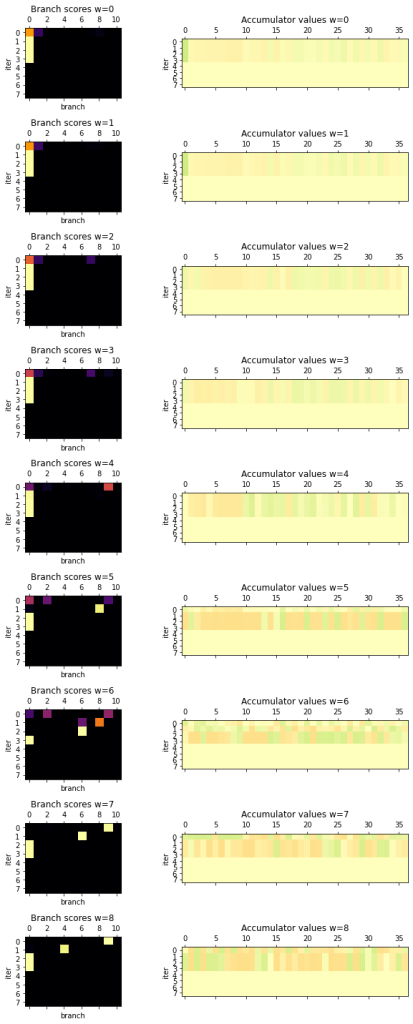
In this multiplication example, ThoughtNet utilized non-zero operators for the first three iterations. The fixed-point criteria was triggered on the fourth iteration, and inference was stopped early.
Source Code
The source code for ThoughtNet and the above experiments is available in the form of a Jupyter notebook on GitHub. I’m making it available under an MIT license.
Future Work
My goal with this project was to familiarize myself with Tensorflow / Keras, and to try out some ideas about networks that could manipulate an internal representation of state through the iterative application of operators. I only had limited time available for this project, and therefore a lot of interesting questions remain for future exploration.
First of all, I only evaluated ThoughtNet on a simple toy problem. It would be interesting to evaluate a similar architecture on more complex data sets and problems, such as language prediction/manipulation, or image processing. Could it be possible to incorporate ideas from ThoughtNet into common transformer architectures?
Training convergence was slow with ThoughtNet in my experiments. The ThoughtNet architecture has a lot of similarity to recurrent neural networks. ThoughtNet likely suffers from vanishing gradient issues when a large number of iterations is involved. The tanh activation function I used might further exarcerbate these issues. More investigation is required to understand and hopefully improve its speed of convergence.
As highlighted in the accuracy evaluation, generalization performance on multiplication tasks was lacking. Additional regularization approaches and/or hyperparameter tuning should be explored to see if those can help improve generalization performance on challenging tasks.
Last but not least, it would be interesting to implement the proposed variable urgency idea, and evaluate its performance and behavioral.
Prior Art
While I wasn’t aware of and didn’t use these papers while working on ThoughtNet, I’d like to call out a few related publications.
All three papers specifically target recurrent neural networks. It is worth pointing out that ThoughtNet’s architecture has some similarity to a recurrent neural net, but works very differently in terms of how it acts on the input sequence. ThoughtNet consumes the whole input sequence at once, and uses attention to repeatedly cross-reference and modify tokens in its internal state, while recurrent neural networks consume one input at a time and don’t use attention mechanisms.
- A. Graves, 2016: Adaptive Computation Time for Recurrent Neural Networks
- Y. Jernite, E. Grave, A. Joulin, T. Mikolov, 2016: Variable Computation in Recurrent Neural Networks
- C. Eyzaguirre, A. Soto, 2020: Differentiable Adaptive Computation Time for Visual Reasoning
Do you know of any other work in this area? Let me know in the comments.
Footnotes
- More accurately, GPT-style LLMs perform constant computation for each generated token. For their typical application in chat assistants, the generation process is stopped after a variable number of tokens. Nonetheless, the same compute is spent on generating a trivial token as one that is tricky to get right. ↩︎
- I was also interested to see if I could design an ANN architecture that can learn “mental operators” – operations that it can apply on a latent mental state space in various combinations in order to complete a given task. You might recognize this goal in the choice of neural architecture taken below, but this is outside the scope of this post. I might write more about it in a future post… ↩︎

Leave a comment