
In my previous post about ThoughtNet, an attention-based neural architecture for variable-compute inference, I highlighted two limitations that I encountered with it:
- Slow and inconsistent convergence during training time
- Poor generalization on multiplication tasks, despite great performance on addition.
While trying to solve the second problem, I stumbled across a surprising way to stabilize training convergence as well.
Was ThoughtNet Cheating?
While attempting to understand why my ThoughtNet models weren’t generalizing much beyond their training data on multiplication problems, I noticed that the operator selection scores in a given iteration were oftentimes divided among multiple operators. In the image below, you can see scores being divided almost evenly between operators (called “branch” in the image) 2 and 0 in iteration 2. I even encountered some examples where three or four operators were being utilized simultaneously in a single step. In essence, the model wasn’t deciding to do just one thing in a given step, but was doing “a bit of” two or three things all at once.

ThoughtNet’s operator selection scores are the output of a softmax function. Softmax is intended as a smooth (everywhere differentiable) approximation of the arg max operator. Additionally, softmax also includes a normalization step, so that the components of its output vectors always sum up to 1. In an idealized case, only one operator should be chosen in a given iteration and receive an operator selection score of 1, while all others receive 0.
The fact that I was seeing split operator selection scores like in the example above made me suspect that the network had found a sneaky way to reduce its thought cost. By squeezing the application of two or more operators into a single iteration, it would be able to perform more complex operations that would normally require multiple steps, thereby reducing the total number of steps required for a task.
A single operator in ThoughtNet is in particular limited by its number of attention heads (3 in my experiments). It is supposed to only access a limited number of token states in any given iteration to produce its output. This limitation was intended to improve generalization on arithmetic problems, as it forces the network to learn simple “digit by digit” steps for solving an addition or multiplication task. Importantly, only being able to access a subset of the tokens at a time should stop the network from trivially memorizing all training input and output pairs. ThoughtNet’s great generalization performance on addition problems to inputs outside of its training set seemed to prove this approach right.
However, combining multiple operators in a single pass could serve as a way to partially bypass this limitation I thought. Furthermore, generating a specifically-balanced softmax output that combines just the right amount of different operators would likely be rather unstable. A small perturbation to the operator selector inputs could easily throw off such a balance. I suspected that the combination of these factors might play a role in limiting the model’s generalization performance on multiplication.
Gaussian Noise Regularization
In an attempt to steer ThoughtNet to converge to more stable, less over-fitted solutions, I decided to add random Gaussian noise to the token states as seen by the operators in each iteration. This kind of regularization does not seem to be used much in the literature, compared to the more common regularization methods of L1 or L2 weight regularization or dropout regularization. However, I have had great results in using Gaussian noise in a different research project of mine, which I’m going to write about another time.
In Tensorflow, the code snippet for adding Gaussian noise to the accumulator tensor is as follows:
if training:
noise = tf.random.normal(
shape=tf.shape(accumulator),
mean=0.0,
stddev=self.state_read_noise,
dtype=tf.float32,
)
accumulator += noiseBy making the token states somewhat noisy1, the network should converge to a solution that relies less on the very specific component values of the state.
In principle, adding noise should only make the network’s task of fitting the training data more difficult. However, what actually happened was rather surprising!
Faster Convergence With Noise
Contrary to my expectations, adding noise into the state values did not seem to make convergence on the training data harder. Rather, at the right amounts, it seemed to make it a little easier and more stable.
The following graphs compare the training loss and the sequence accuracy (fraction of correctly solved input tasks) through the first 600 epochs of training. The no_noise line corresponds to training without any added noise, while the other values have Gaussian state noise applied at various standard deviations. Besides the addition of noise, all training parameters and the training data set were the same as in my previous post. Note that the learning rate schedule has a reduction in training rate at epoch 500.

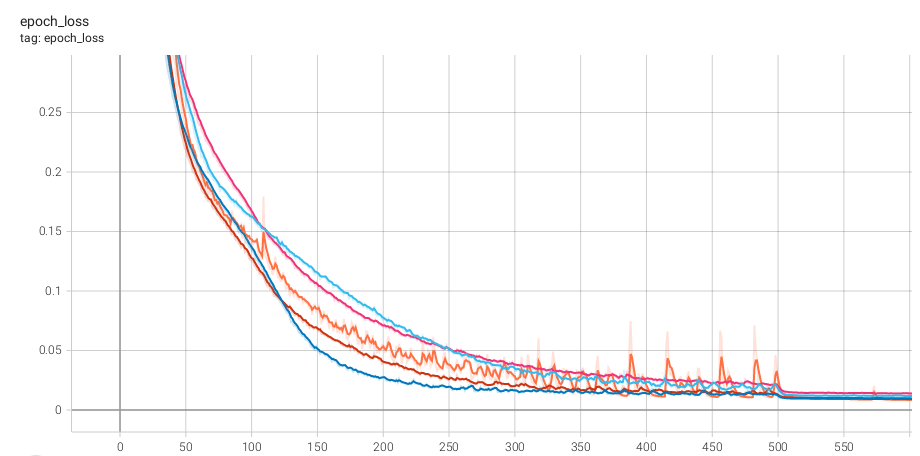
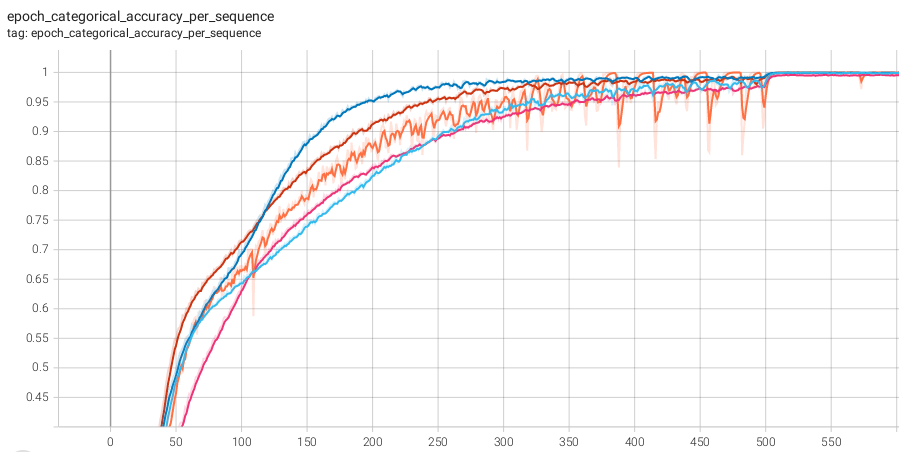
You can see that convergence on this problem was especially fast with a standard deviation of 0.2, though 0.3 also improved training over the baseline. Standard deviations of 0.1 and 0.4 on the other hand still added stability, but overall led to slower conversion.
Some interesting things happened in terms of the thought cost throughout the training process (see plot below). In ThoughtNet, the thought cost is the amount to which the network utilizes non-zero operators in its inference. See my previous post for details. Training without noise initially maintained a high level of thought cost, which however dropped quickly once the learning rate got reduced after epoch 500. A noise level of stddev=0.1 maintained a relatively high level of thought cost throughout the training process. This behavior would be consistent with my initial hypothesis that ThoughtNet without noise can learn to fine-tune its operator selection in a way that allows it to combine multiple operators in a single iteration.
However, a rather different effect appears once the noise level is increased further. Starting with stddev=0.2, thought costs drop to a significantly lower level than either no noise or stddev=0.1 early during training, and remain there until the end. I hypothesize that the added noise might give ThoughtNet an additional push towards switching to the zero operator early on, as any iteration that utilizes a non-zero operator introduces additional noise. Interestingly, performance does not seem to suffer. More research would be needed to fully understand this phenomenon.

Improved Generalization?
In terms of addition, all tested noise levels below stddev=0.4, including no noise at all, had comparable performance, with at least 99% sequence accuracy on all tested input sizes. At stddev=0.4 accuracy started to degrade notably. A noise level of stddev=0.3 did marginally better than other settings, yielding perfect accuracy on all validation samples, though the differences were small.
When it came to the more interesting problem of multiplication, results were a little inconsistent. A noise level of stddev=0.2 yielded the best accuracy for 3-digit multiplication (1*2 digits or 2*1 digits) at 93%, while 4-digit multiplication (2*2 digits) worked best at a slightly higher noise level of stddev=0.3. However, 3-digit accuracy was actually worse with stddev=0.3 than with no noise at all. Given the large variations, I’d likely need to repeat this experiment across multiple runs to get more reliable results, but I have not had time to do that yet. I suspect that the random weight initialization of the network prior to training might play a big role in these outcomes.
| 2 digits (1∘1) | 3 digits (1∘2 / 2∘1) | 4 digits (2∘2) | 5 digits (2∘3 / 3∘2) | 6 digits (3∘3) | |
|---|---|---|---|---|---|
| no noise addition | 1 | 0.99 | 0.99 | 0.99 | 0.99 |
| noise stddev=0.1 addition | 1 | 0.99 | 0.99 | 0.99 | 0.99 |
| noise stddev=0.2 addition | 1 | 1 | 1 | 0.99 | 0.99 |
| noise stddev=0.3 addition | 1 | 1 | 1 | 1 | 1 |
| noise stddev=0.4 addition | 0.98 | 0.93 | 0.89 | 0.80 | 0.96 |
| no noise multiplication | 1 | 0.88 | 0.51 | ||
| noise stddev=0.1 multiplication | 1 | 0.91 | 0.62 | ||
| noise stddev=0.2 multiplication | 1 | 0.93 | 0.58 | ||
| noise stddev=0.3 multiplication | 0.99 | 0.77 | 0.65 | ||
| noise stddev=0.4 multiplication | 0.99 | 0.85 | 0.53 |
Closing Thoughts
I set out to find a way to improve ThoughtNet performance on multiplication tasks. Multiplication performance on an independent test set did improve beyond the level that would be expected if the network merely memorizes the training set, however the improvement was small.
I also attempted several other forms of implicit regularization, such as reducing the number of attention heads available to a given operator. Doing so slows down convergence (as expected this time – I made the problem harder), but still does not appear to improve generalization performance on multiplication tasks meaningfully.
To be fair, multi-digit multiplication is quite a difficult problem for a neural network like ThoughtNet to learn. The naive long multiplication algorithm for multiplying two numbers of arbitrary size requires a quadratic number of steps, i.e. O(num_digits^2), and quite a bit of state to keep track of. If we assume for a moment that ThoughtNet would learn something akin to long multiplication, and each of its operator applications would be equivalent to either a single-digit addition or multiplication, then for our 2*2 digit multiplications, ThoughtNet would have to perform a total of 4 single-digit multiplications, up to 8 single-digit additions, plus an appropriate number of shifts. The order in which these operations are performed would need to be carefully sequenced and coordinated across the different tokens, as to not prematurely overwrite dimensions in the internal state space that are still needed by another token. All that might just be too much to ask for, especially with the relatively small network size and limited training sets that I’m using.
On a positive note, Gaussian noise proved useful in improving training-time convergence, presumably by making the network more robust.
An updated Jupyter notebook for ThoughtNet that includes the Gaussian noise regularization can be found on Github.
Footnotes
- One small but important detail specific to ThoughtNet is that the state noise is only applied for the non-zero operators. The hard-coded zero (or identity) operator still carries forward the unchanged state value into the next iteration, without any noise being added. ↩︎

Leave a comment